










NVLink: как работает «кровеносная система» современных ИИ-суперкомпьютеров
В эпоху гигантских нейросетей узким местом стала не мощность чипов, а скорость обмена данными. NVLink решает эту проблему, объединяя видеокарты в единый суперкомпьютер с общей памятью. В этом гиде разберём архитектуру технологии: от различий с PCIe до коммутаторов NVSwitch и применения во флагманских серверах для обучения ИИ.
Введение: эпоха межсоединений и преодоление «стены памяти»
В современной парадигме высокопроизводительных вычислений (HPC) и искусственного интеллекта (AI) произошёл фундаментальный сдвиг. Если раньше узким местом системы была тактовая частота процессора или количество ядер, то в эру гигантских нейросетей на передний план вышла проблема перемещения данных. Закон Мура продолжает обеспечивать рост плотности транзисторов, но скорость передачи информации между чипами не поспевает за их вычислительной мощностью.
Именно в этом контексте технология NVLink стала не просто вспомогательным компонентом, а центральным элементом архитектуры, определяющим возможности современных дата-центров. Без неё вычисления масштаба ChatGPT или Claude были бы физически невозможны.
В этом материале мы разберём архитектуру NVLink, эволюцию от Pascal до Rubin, отличия от PCIe и роль этой технологии в современных научных лабораториях и центрах обработки данных.
Что такое NVLink
NVLink — это разработанная компанией NVIDIA технология высокоскоростного интерконнекта (interconnect) для создания прямых соединений типа «точка-точка» между графическими процессорами (GPU), а также между GPU и центральными процессорами (CPU).
NVLink — высокоскоростной интерконнект для соединения GPU
В отличие от стандартных сетевых протоколов, которые дробят данные на пакеты и требуют сложной обработки через стек драйверов, NVLink работает на уровне семантики памяти. Это означает, что устройства могут «общаться» друг с другом, используя обычные инструкции загрузки и сохранения (Load/Store), минуя операционную систему. Для прикладного ПО массив видеокарт, соединённых через NVLink, выглядит как одно логическое устройство с общим пулом памяти и ядер.
Принцип работы NVLink на уровне семантики памяти
Физически это последовательный интерфейс с дифференциальными парами, который поддерживает агрегацию. Каналы можно объединять (bonding) для масштабирования скорости. Например, в архитектуре Hopper каждый чип H100 имеет 18 линков четвёртого поколения. В сумме такая высокоскоростная шина обеспечивает обмен данными на скоростях, недостижимых для традиционных решений.
Технология реализует концепцию Scale-Up (вертикальное масштабирование внутри узла), тогда как Ethernet или InfiniBand отвечают за Scale-Out (горизонтальное масштабирование между серверами). Без NVLink современные задачи в области ИИ упёрлись бы в «стену памяти» ещё несколько лет назад.
Ключевые преимущества NVLink перед PCIe
Доминирование PCI Express (PCIe) в индустрии обусловлено его универсальностью. Но в задачах High Performance Computing (HPC) и Deep Learning универсальность требует слишком больших компромиссов.
1. Пропускная способность (Bandwidth)
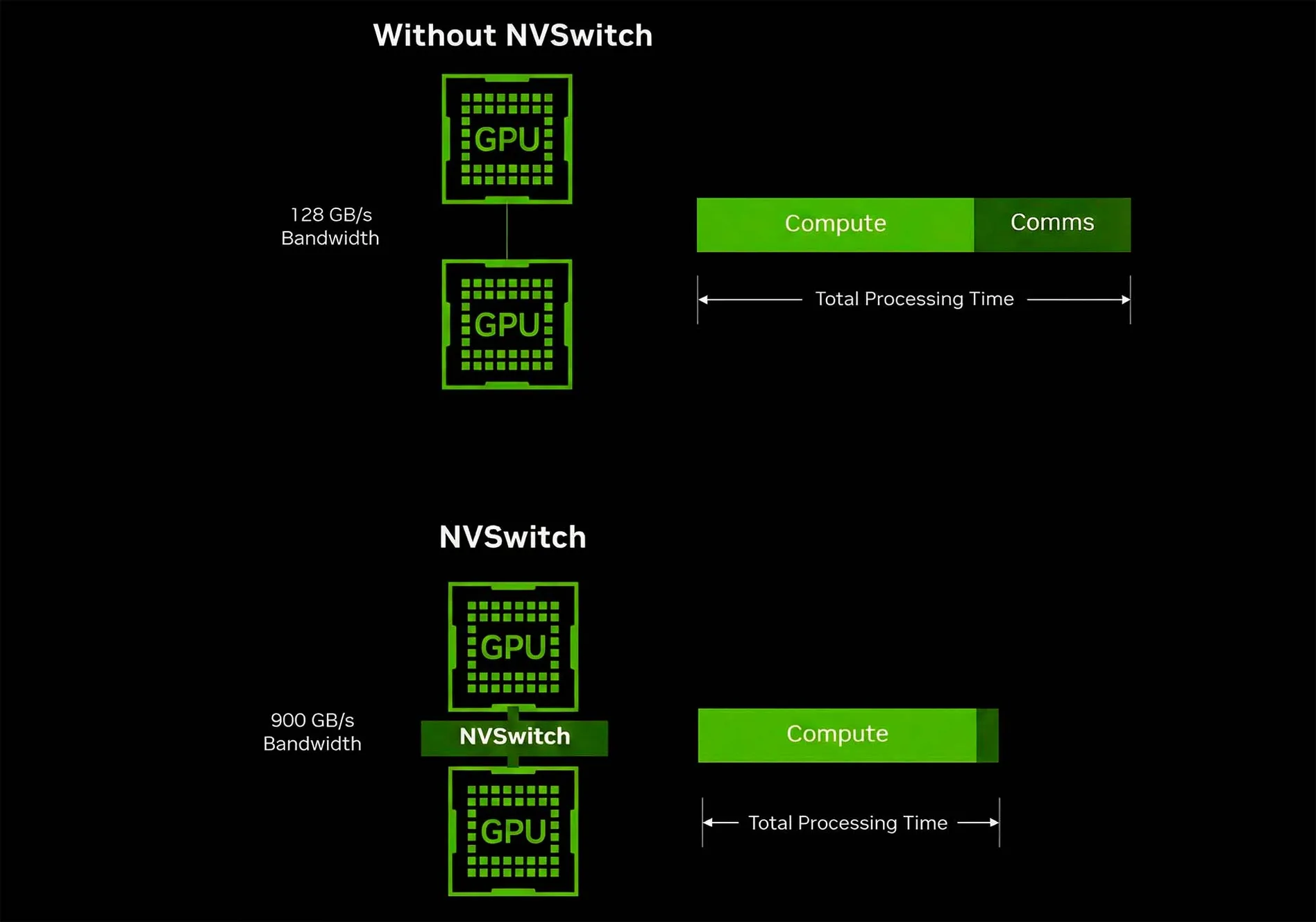
Разрыв в скорости между NVLink и PCIe колоссален. Стандартный интерфейс PCIe Gen 5.0 x16 выдаёт теоретический максимум около 64 ГБ/с (в обе стороны) или 128 ГБ/с при дуплексе. Для сравнения, пропускная способность NVLink 4.0 (архитектура Hopper) составляет 900 ГБ/с на один GPU. Это более чем в 14 раз быстрее.
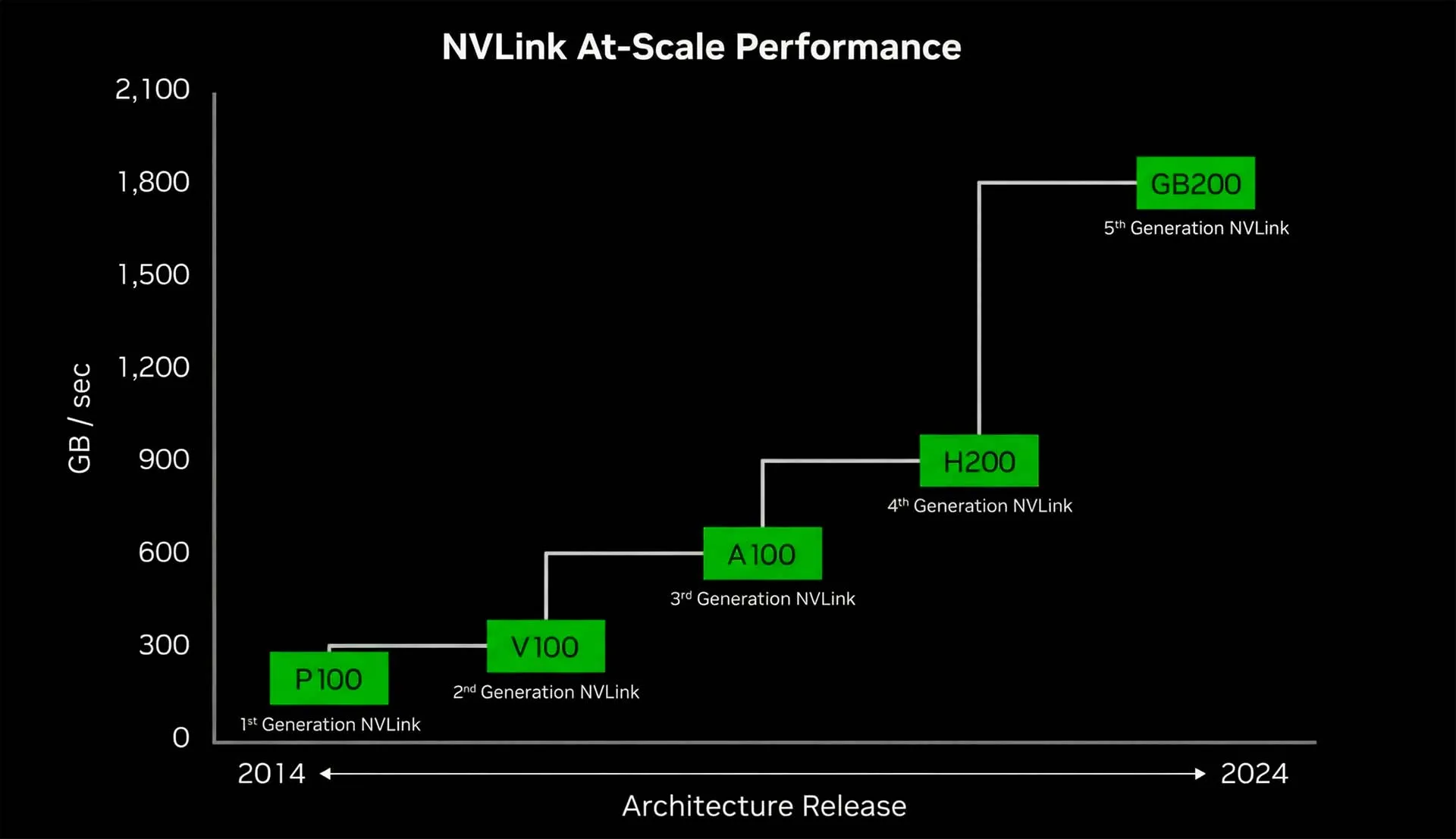
Сравнение пропускной способности NVLink и PCIe
В новейшем поколении NVLink 5.0 (архитектура Blackwell) этот показатель удвоен до 1800 ГБ/с (1,8 ТБ/с). Такая пропускная способность необходима, чтобы соответствовать внутренней памяти HBM3e, которая работает на скоростях 3–8 ТБ/с. Если интерконнект медленный, мощные ядра GPU будут простаивать в ожидании данных.
2. Латентность и накладные расходы
При обмене данными через PCIe трафик часто проходит через корневой комплекс (Root Complex) центрального процессора. Даже с технологиями Peer-to-Peer это создаёт задержки. NVLink обеспечивает прямое соединение с минимальной латентностью. Поддержка когерентности кэша и атомарных операций позволяет видеокартам синхронизироваться на порядки быстрее, что критично для обучения нейросетей, где обмен градиентами происходит постоянно.
3. Эффективность использования памяти (Memory Pooling)
PCIe изолирует память устройств. Чтобы GPU 1 мог работать с данными GPU 2, их нужно копировать. NVLink позволяет реализовать Unified Memory (унифицированную память). Приложения видят VRAM всех карт как единое адресное пространство. Например, две профессиональные видеокарты RTX A6000 по 48 ГБ могут работать с единым пулом в 96 ГБ, загружая сцены или модели, которые физически не помещаются в один ускоритель. Это ключевое преимущество технологии memory pooling.
Сравнение поколений интерфейсов:
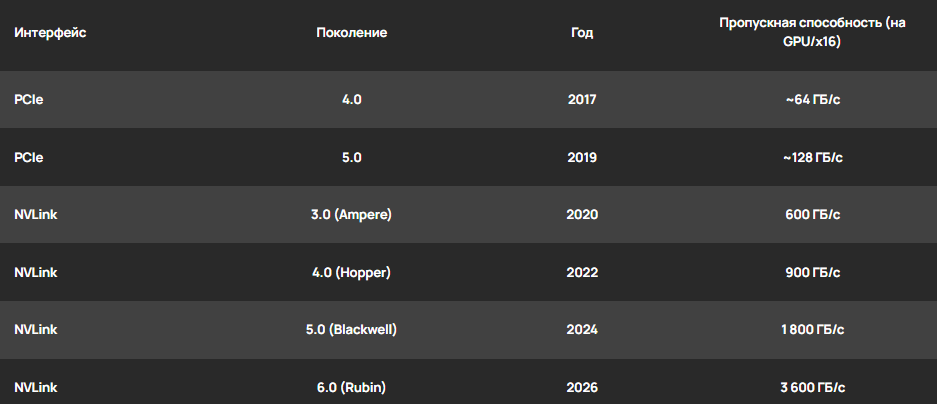
Сравнение поколений интерфейсов NVLink
Архитектура и реализация NVLink
Реализация технологии варьируется от простых мостов в рабочих станциях до сложнейших коммутационных узлов в суперкомпьютерах. Понимание этих различий важно при выборе оборудования под конкретный пул задач.
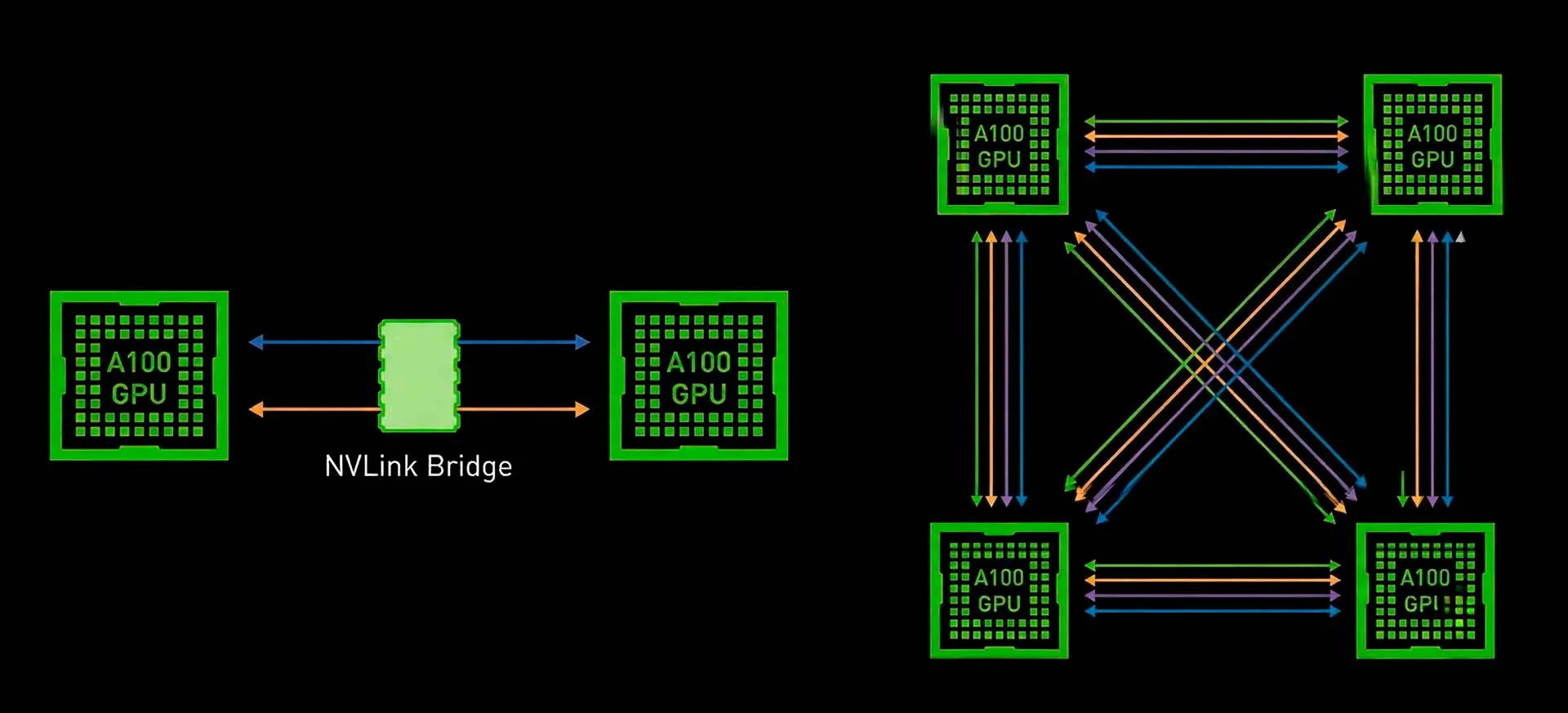
NVLink Bridge для рабочих станций
В сегменте профессиональной визуализации технология реализуется через физический компонент — NVLink Bridge. Это жёсткая печатная плата, соединяющая разъёмы на верхней грани двух ускорителей.
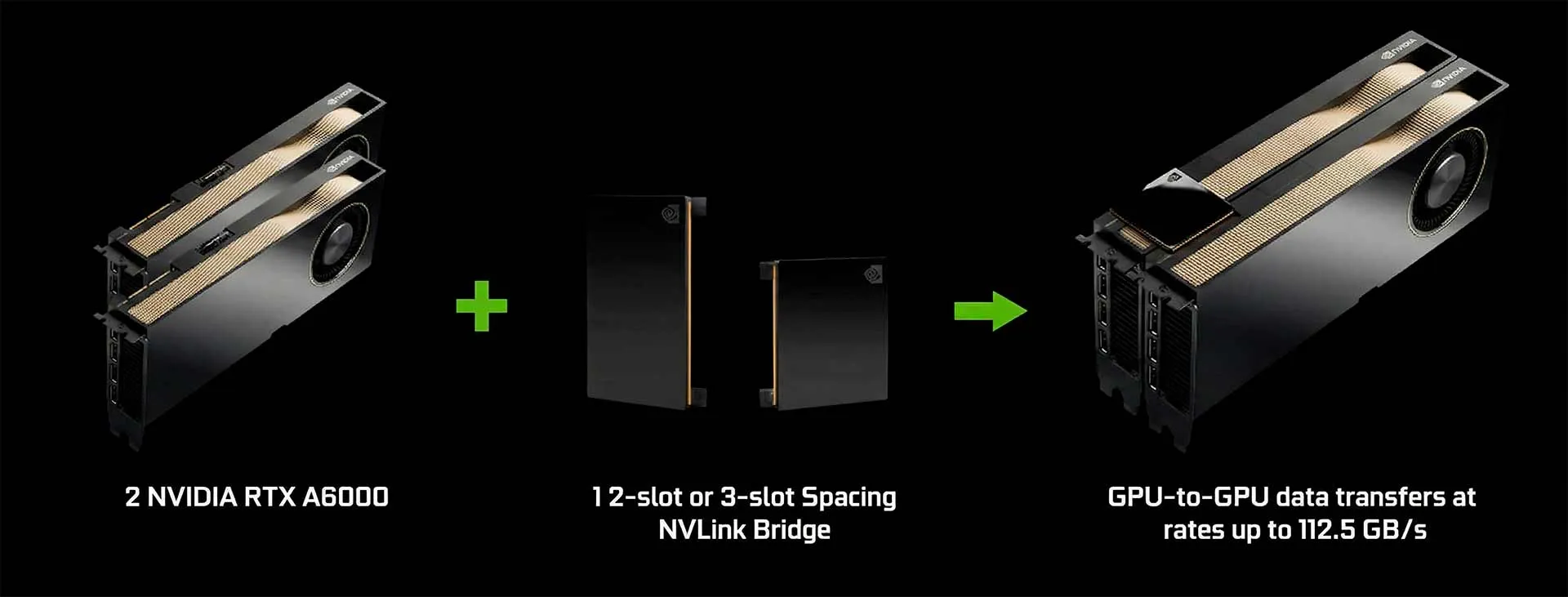
RTX A6000 с мостами NVLink
- Топология: точка-точка (Point-to-Point)
- Применение: рабочие станции с картами серии NVIDIA RTX
- Ограничения: обычно соединяет только 2 карты
Это решение идеально подходит для рендеринга тяжёлых сцен в V-Ray или работы с большими датасетами в Data Science, где важен объём соединённой памяти. Важно отметить, что поддержка мостов исключена из потребительских видеокарт GeForce начиная с RTX 4090.
NVSwitch: коммутационная фабрика
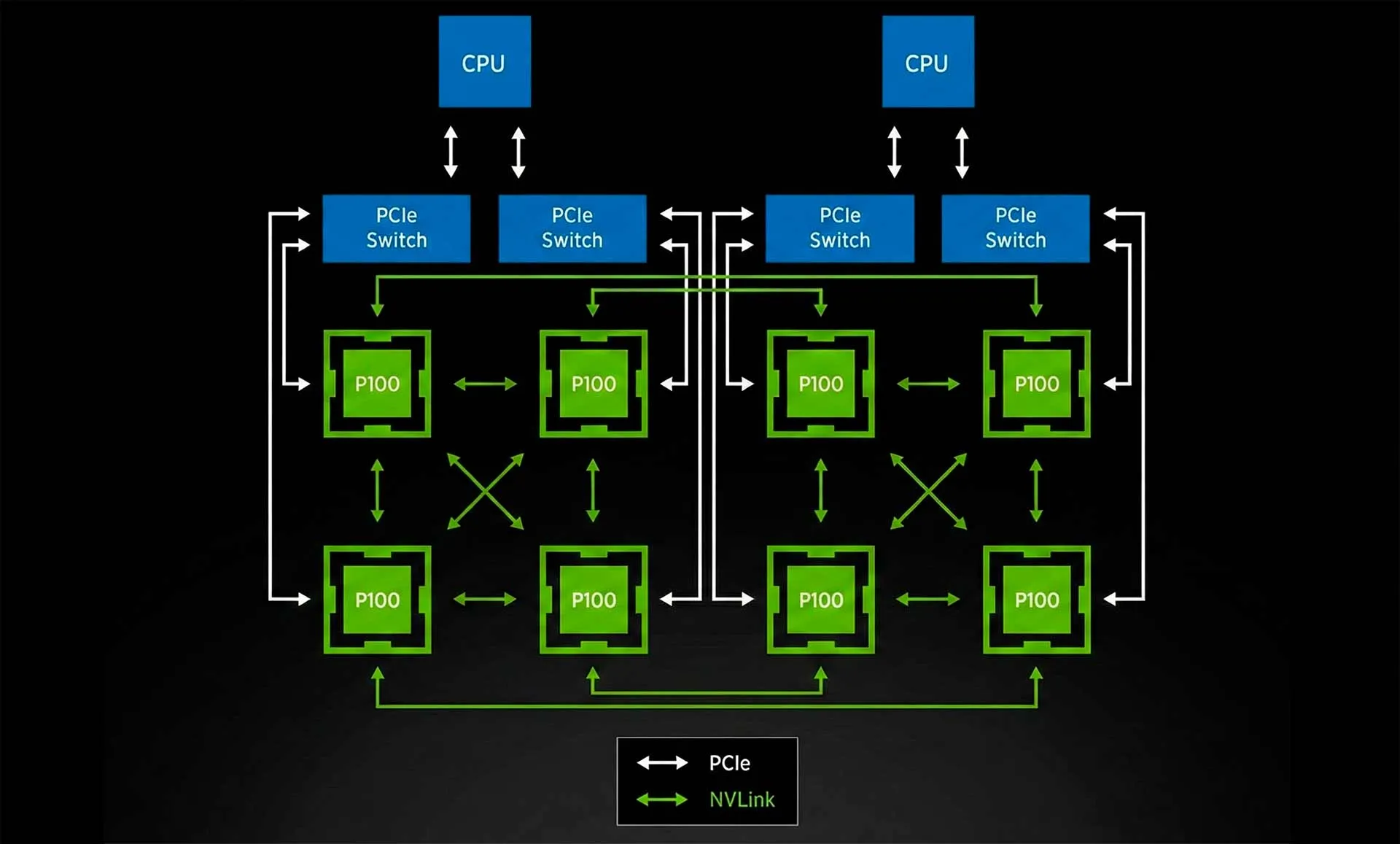
Для серверов класса High-End (HGX, DGX) прямого соединения «каждый с каждым» недостаточно из-за сложности разводки плат. Здесь используют NVSwitch — специализированный чип-коммутатор.

NVSwitch — чип-коммутатор для серверов HGX/DGX
Вместо прямого соединения видеокарт друг с другом, каждый графический процессор подключается к чипам NVSwitch на системной плате. Это создаёт полносвязную (All-to-All) неблокируемую сеть. Любой процессор может передавать данные любому другому на полной скорости.
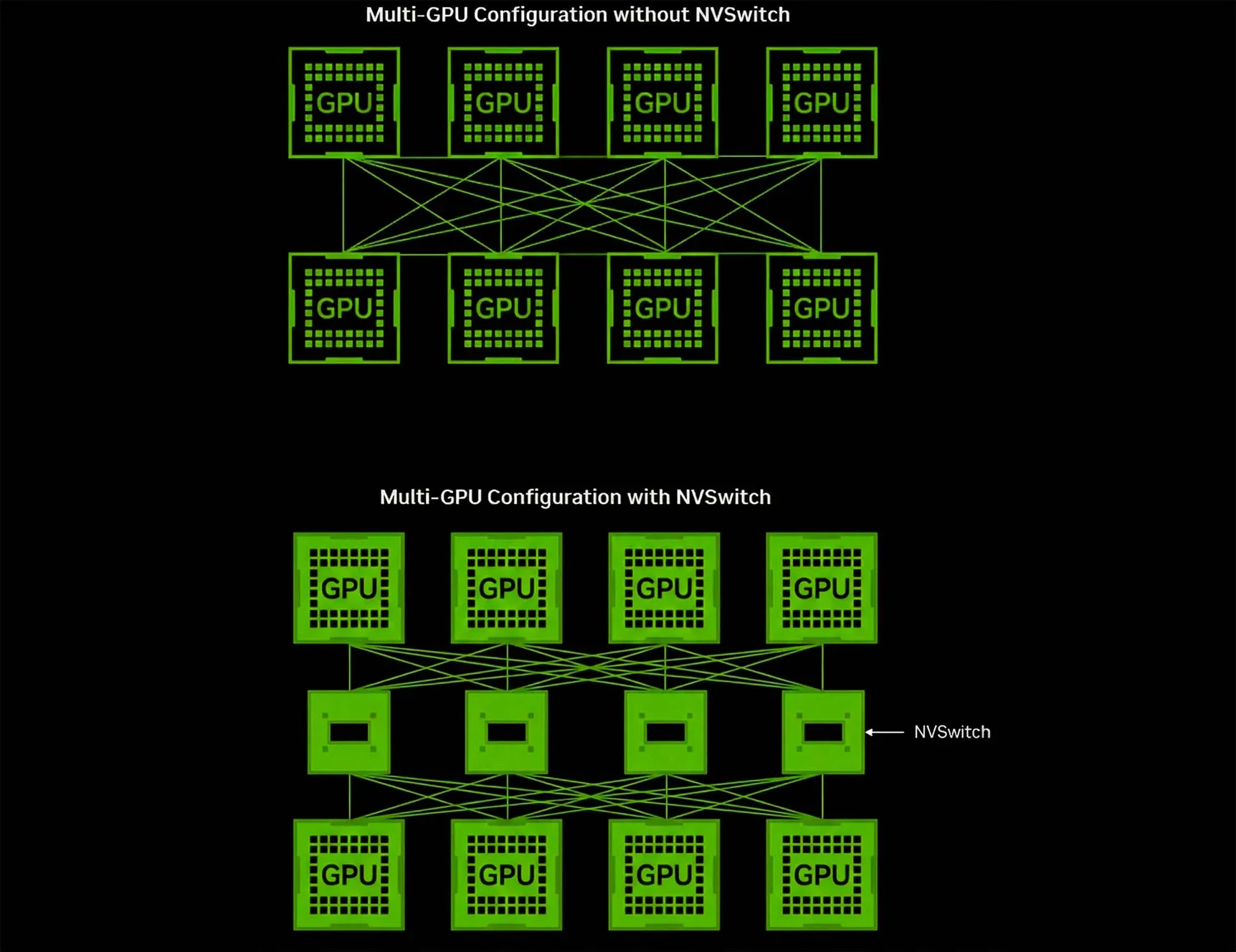
Полносвязная архитектура NVSwitch
Современные коммутаторы NVSwitch поддерживают протокол SHARP (Scalable Hierarchical Aggregation and Reduction Protocol). Он позволяет выполнять математические операции редукции (например, суммирование результатов обучения) прямо внутри коммутатора, разгружая сами GPU.
Сравнение реализаций:
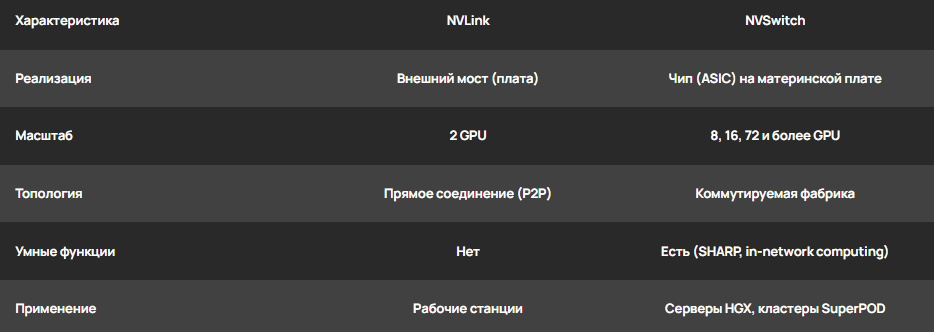
Сравнение различных реализаций NVLink
NVLink-C2C для суперчипов
Третья итерация технологии — NVLink-C2C (Chip-to-Chip). Это когерентный интерфейс для соединения кристаллов внутри одного корпуса. Используется в суперчипах Grace Hopper (GH200) и Grace Blackwell (GB200) для связи CPU Grace и GPU Hopper/Blackwell.
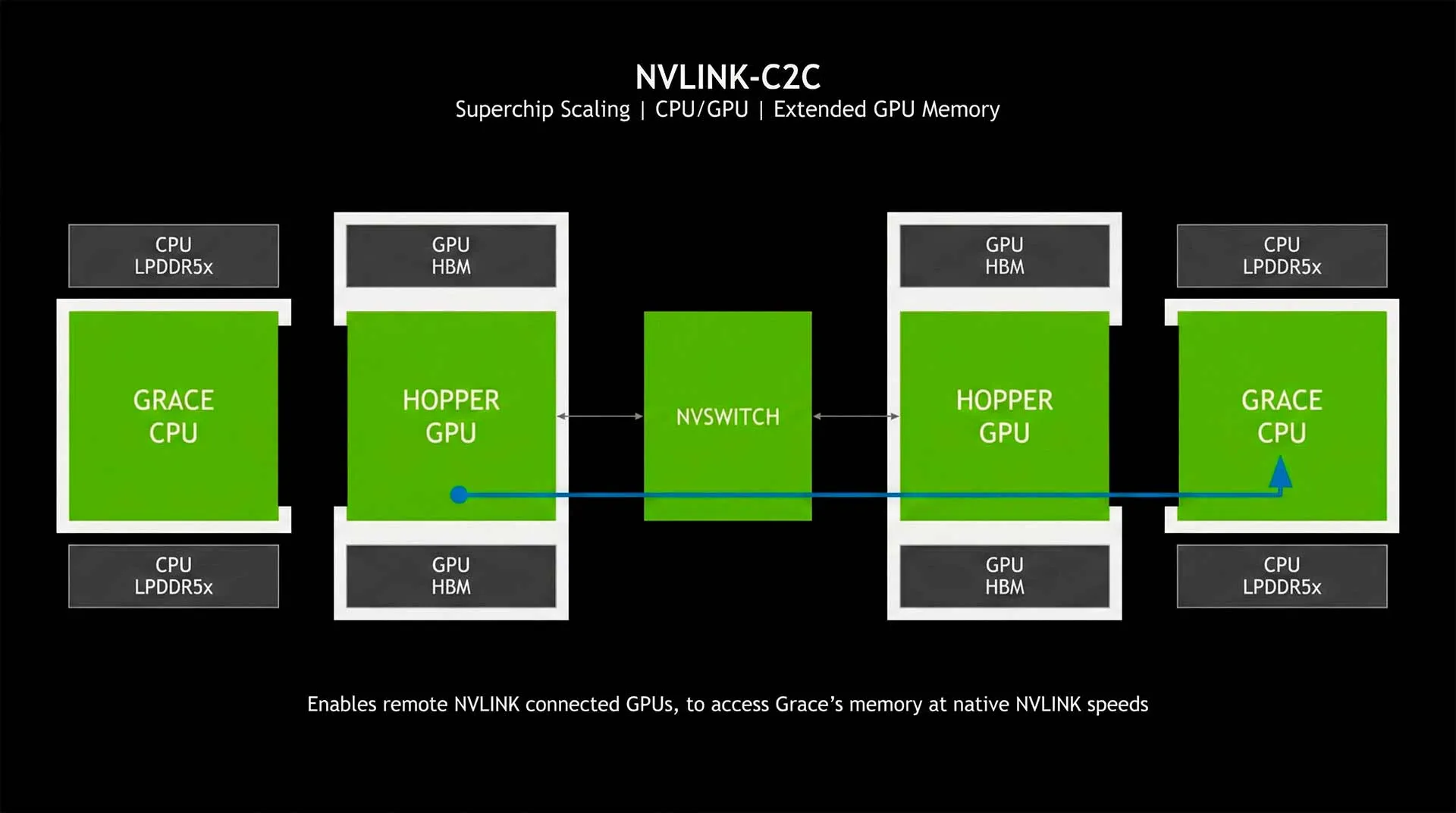
NVLink-C2C для соединения кристаллов в суперчипах Grace Hopper/Blackwell
Интерфейс обеспечивает скорость 900 ГБ/с (в 7 раз быстрее PCIe Gen 5). Это позволяет графическому чипу обращаться к оперативной памяти процессора почти так же быстро, как к своей собственной, расширяя доступный объём памяти до 480+ ГБ на один ускоритель. Это революция для инференса «тяжёлых» моделей.
Флагманские системы с NVLink
Эволюция высокоскоростного интерфейса неразрывно связана с развитием вычислительных платформ. Решения на базе NVLink определяют облик современных дата-центров.
NVIDIA HGX H200 (архитектура Hopper)
Стандарт де-факто для обучения моделей уровня GPT-4 в 2024 году. Система представляет собой плату с 8 GPU H200 (141 ГБ HBM3e), объединёнными через 4 чипа NVSwitch 3.0. NVLink 4.0 здесь обеспечивает агрегированную скорость памяти более 38 ТБ/с.
NVIDIA GB200 NVL72 (архитектура Blackwell)
Инновационная архитектура масштаба стойки (Rack-Scale). Это не просто сервер, а единый вычислительный кластер из 72 GPU B200, соединённых медным бэкплейном (backplane) через NVLink 5.0. Медь используется вместо оптики внутри стойки для снижения задержек и энергопотребления. Стойка функционирует как один гигантский GPU с производительностью 1,4 экзафлопс для задач ИИ.
NVIDIA Vera Rubin (архитектура Rubin)
Перспективная платформа, релиз которой состоится в 2026 году. Будет оснащена NVLink 6.0 с пропускной способностью 3600 ГБ/с на чип. Система NVL72 на базе Rubin обеспечит агрегированную пропускную способность сети в 260 ТБ/с, что необходимо для агентского ИИ (Agentic AI), работающего в непрерывном цикле рассуждений.
Сравнение флагманских систем:
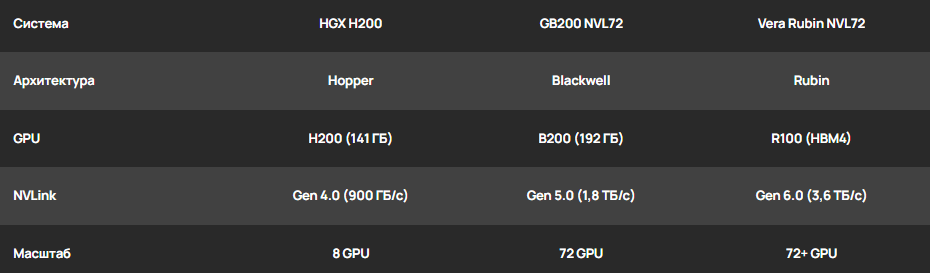
Сравнение флагманских систем на базе NVLink
Сферы применения NVLink
Технология стала катализатором прогресса в нескольких отраслях, где нужна экстремальная скорость обмена данными. Вот основные сферы использования.
Искусственный интеллект и Deep Learning
Это основной драйвер развития технологии. Обучение моделей с триллионами параметров невозможно на одном ускорителе. Используется техника Tensor Parallelism, когда слои нейросети «разрезаются» и распределяются по разным картам. Каждый шаг требует синхронизации. Без NVLink видеокарты простаивали бы 90% времени. Сферы применения включают обучение LLM, генеративный ИИ и компьютерное зрение.

DigitalRazor Scale
Высокопроизводительные вычисления (HPC)
В научном моделировании (прогноз погоды, молекулярная динамика, квантовая хромодинамика) задачи разбиваются на сетку, распределённую по памяти кластера. Границы этих сеток должны постоянно обновляться. Низкая латентность NVLink позволяет решать задачи симуляции фолдинга белков или ядерного синтеза за дни, а не недели.

DigitalRazor HPC8000 для высокопроизводительных вычислений
Профессиональная визуализация
В индустрии VFX сцены становятся всё детальнее. Объём геометрии часто превышает 48 ГБ. Объединение памяти двух карт RTX A6000 даёт художнику 96 ГБ буфера. Это позволяет рендерить сцены целиком в GPU, избегая медленного свопинга в ОЗУ.

DigitalRazor DevBox
Data Science и аналитика
Библиотеки NVIDIA RAPIDS позволяют выполнять SQL-запросы и ETL-процессы прямо в видеопамяти. NVLink позволяет распределять огромные таблицы данных (Dataframes) по нескольким ускорителям и выполнять операции Join/GroupBy с высочайшей скоростью, заменяя собой целые кластеры CPU-серверов.

Семейство GPU-серверов DigitalRazor RackStation
Как NVLink меняет архитектуру вычислений
Внедрение интерконнекта такого уровня привело к смене парадигмы того, как строятся центры обработки данных. Традиционная модель «CPU — хозяин, GPU — периферия» уходит в прошлое.
- Дезагрегация и модульность: с появлением систем вроде GB200 единицей вычислений становится стойка. NVLink создаёт «супер-мозг» внутри стойки, а InfiniBand соединяет эти стойки между собой.
- Энергоэффективность: передача данных по NVLink (особенно по меди внутри стойки) потребляет значительно меньше энергии на бит информации, чем PCIe или оптика. В масштабах мегаваттных дата-центров это даёт огромную экономию.
- Конфиденциальные вычисления: последние поколения интерфейса поддерживают шифрование данных на лету, создавая защищённые анклавы для обработки медицинских или финансовых данных.
Облачные вычисления также трансформируются: провайдеры теперь могут предлагать инстансы с гарантированной пропускной способностью между виртуальными машинами, используя нарезку (partitioning) ресурсов NVSwitch.
Заключение
NVLink прошёл путь от экспериментальной технологии до кровеносной системы современного искусственного интеллекта. Стирание границ между чипами позволяет решать задачи, которые вчера казались невозможными. Понимание возможностей этого интерфейса — ключевой фактор при проектировании инфраструктуры для вычислений нового поколения.
Ключевые особенности технологии NVLink:
- Высокоскоростной интерконнект с пропускной способностью до 1,8 ТБ/с (NVLink 5.0)
- Прямое соединение GPU-GPU и GPU-CPU с минимальной латентностью
- Когерентность кэша и поддержка атомарных операций
- Объединение памяти (Memory Pooling) нескольких ускорителей
- Реализации: NVLink Bridge (2-way), NVSwitch (8-way), NVLink-C2C (суперчипы)
- Применение: обучение ИИ, HPC, профессиональная визуализация, аналитика данных
- Флагманские системы: HGX H200, GB200 NVL72, перспективная Rubin
- Ключевое преимущество перед PCIe: скорость выше в 14+ раз
Источник: digital-razor.ru